
Deep learning neural networks
Deep learning is a collection of algorithms and topologies that may be used in a wide range of scenarios. While deep learning is not a new concept, it is fast developing due to the combination of massively layered neural networks and the use of GPUs to accelerate its execution. Big data has also supported this growth. Because deep learning relies on training neural networks with sample data and rewarding them based on their performance, the more data accessible, the better these deep learning structures will be developed.
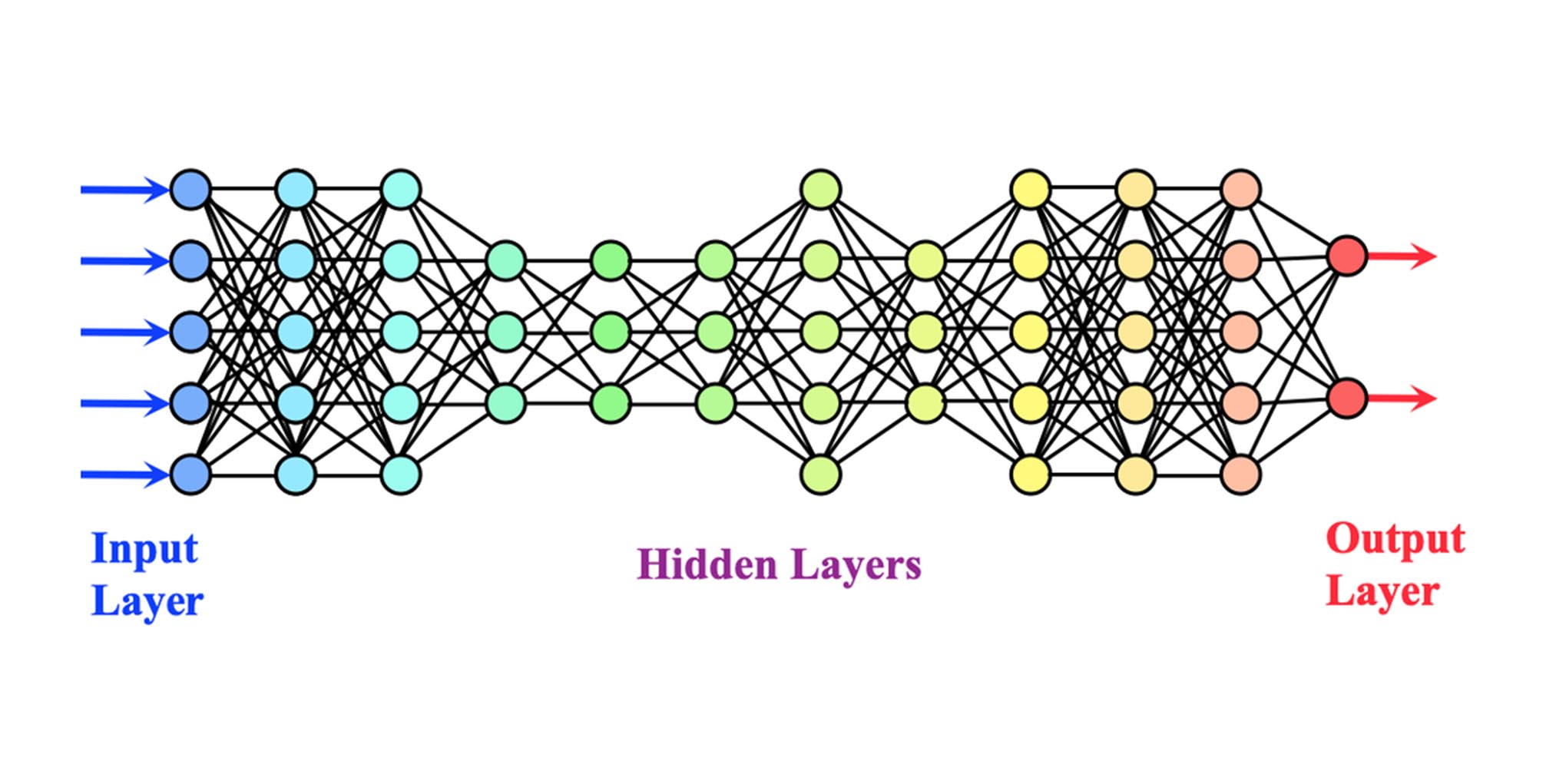
Deep learning architectures are classified into supervised and unsupervised learning
Supervised learning: refers to the problem space where the training data has a clear label for the target to be predicted.
Unsupervised learning: refers to the problem space where the training data does not contain a target label. refers to the problem space where the training data does not contain a target label.
and introduces several popular deep learning architectures:
Long short-term memory (LSTM) and convolutional neural networks (CNNs) are two of the oldest approaches to deep learning architectures.
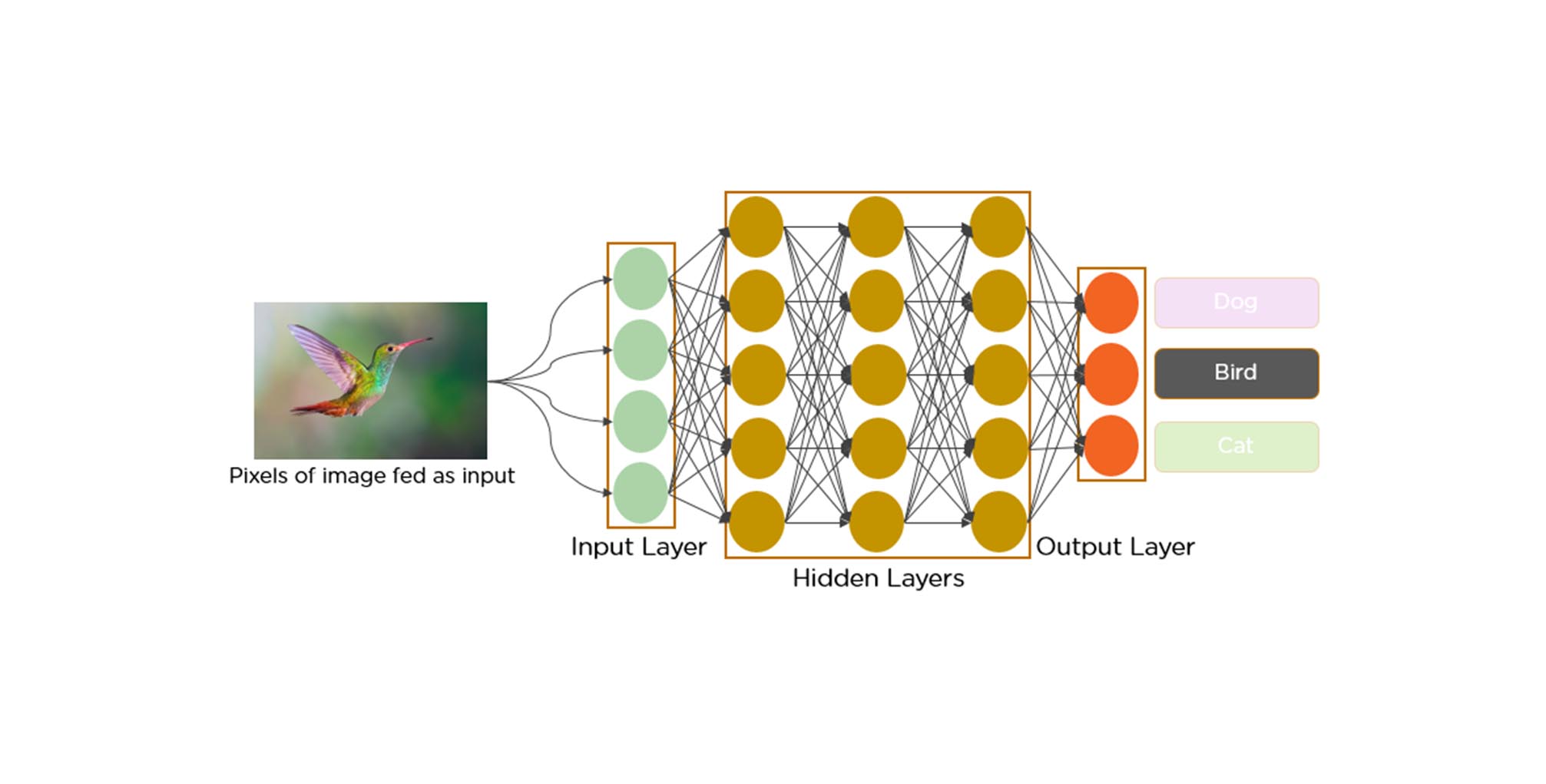
Convolutional neural networks (CNNs): A CNN is a multilayer neural network inspired by the animal visual cortex, used in image-processing applications. The first CNN was created by Yann LeCun for handwritten character recognition. The LeNet CNN architecture consists of several layers for feature extraction and classification, including convolution, pooling, and a multilayer perceptron. The final output layer identifies features of the image, trained using back-propagation. Deep learning neural networks, with deep processing layers, convolutions, pooling, and a connected classification layer, have been successfully applied for image processing, video recognition, and natural language processing tasks
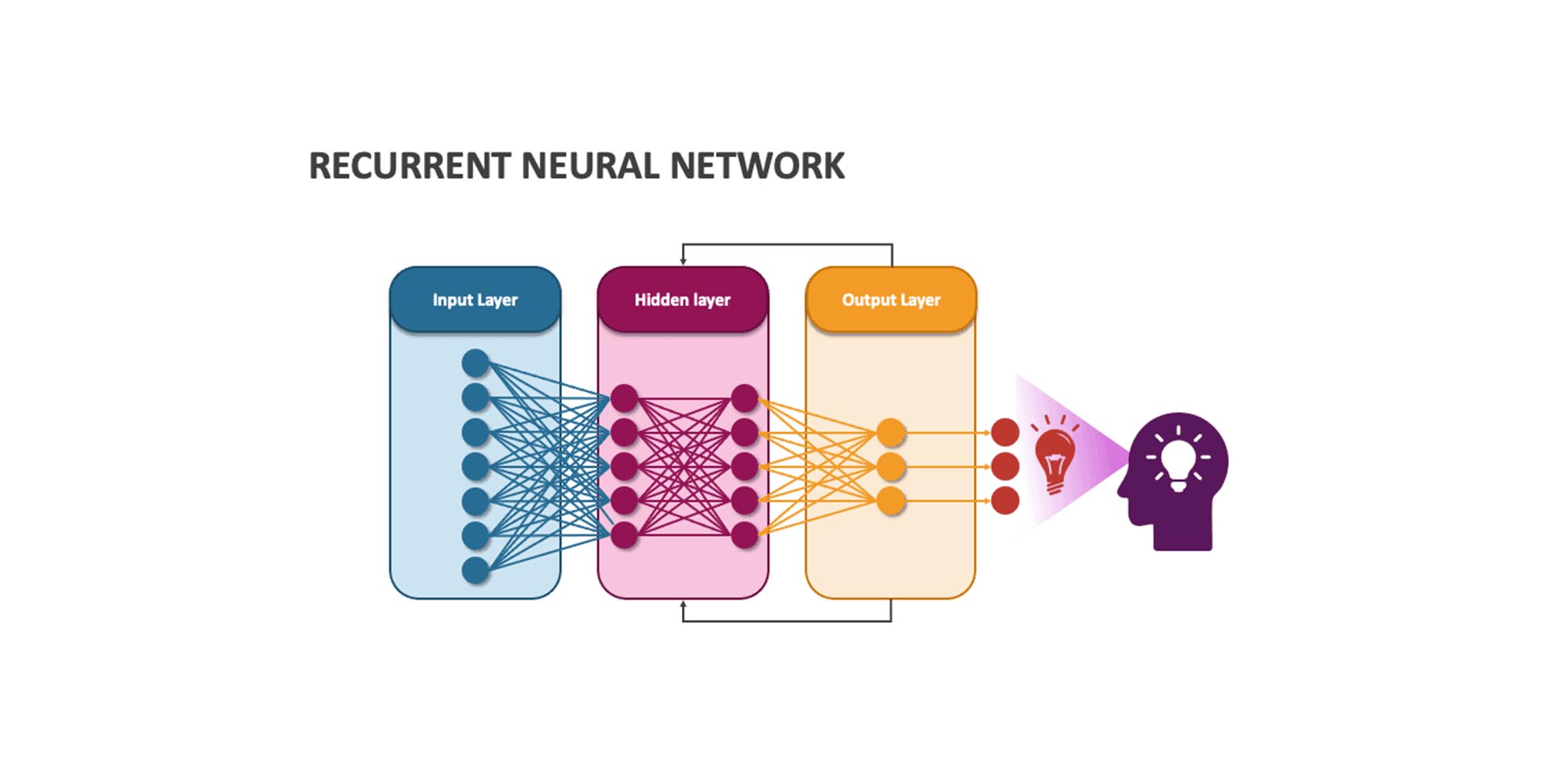
Recurrent neural networks (RNNs): Recurrent neural networks (RNNs) are fundamental network architectures used in deep learning. They differ from multilayer networks by having connections that feed back into prior layers, allowing them to maintain memory and model problems in time. Feedback is the key differentiator. RNNs can be trained using standard back-propagation or back-propagation in time (BPTT), with applications in speech and handwriting recognition.
Long short-term memory (LSTM): The LSTM, created in 1997, is an RNN architecture used in everyday products like smartphones and IBM Watson for conversational speech recognition. It consists of a memory cell with three gates: input, forget, and output. The training algorithm, BPTT, optimizes these weights based on network output error. Recent applications of CNNs and LSTMs include image and video captioning systems, where the CNN processes images or videos, and the LSTM converts the output into natural language.
Self-organizing map (SOM): invented by Dr. Teuvo Kohonen in 1982, is an unsupervised neural network that reduces the dimensionality of input data. SOMs use weights as a characteristic of nodes, with random weights initialized for each feature. The best matching unit (BMU) is the node with the least distance, and other units are assigned to the cluster. SOMs have no activation function and no target labels, eliminating error and backpropagation. Applications include dimensionality reduction, radiant grade results, and cluster visualization.
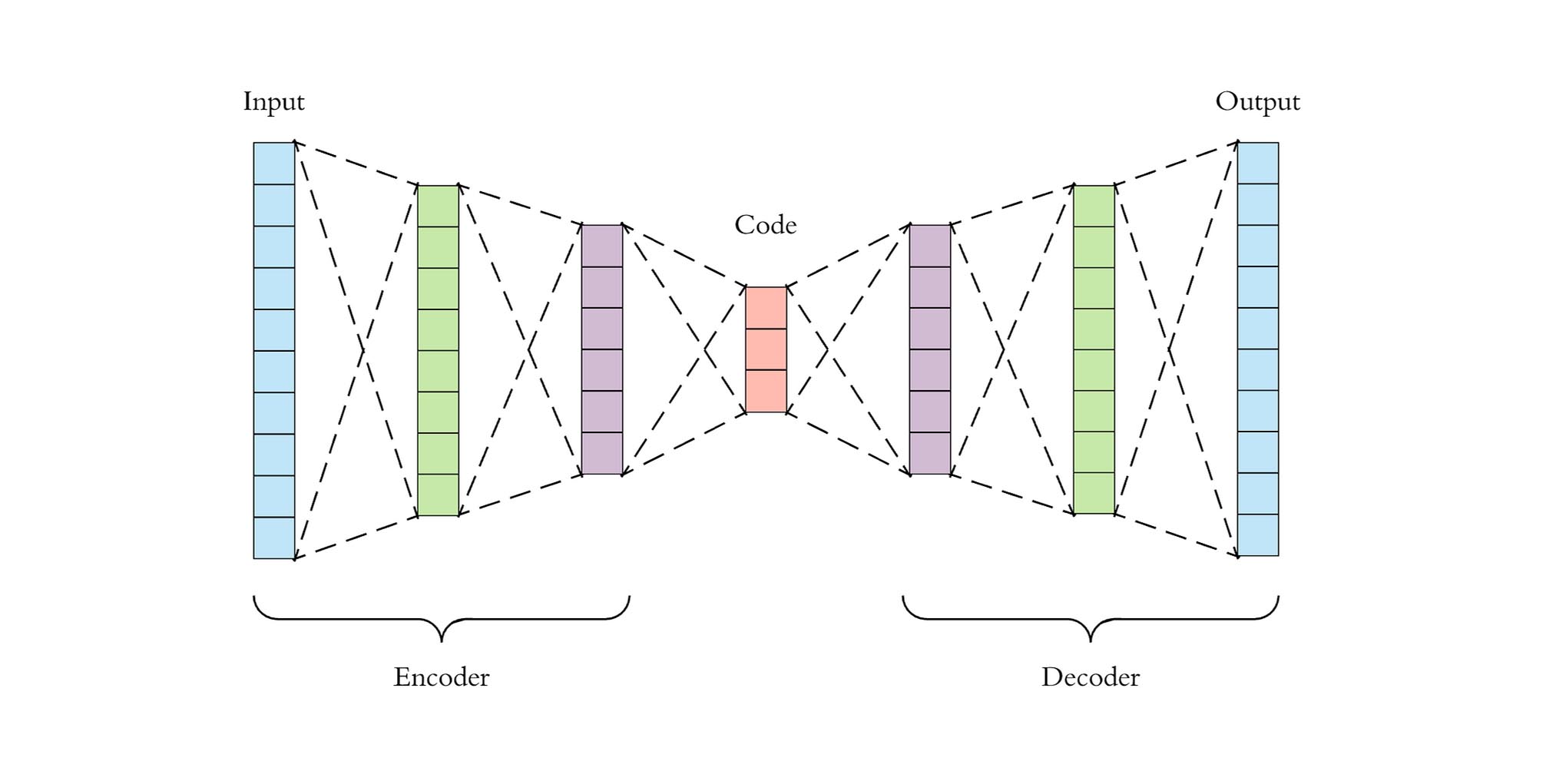
Autoencoders (AE): LeCun introduced autoencoders, a type of artificial neural network, in 1987. They are composed of three layers: input, hidden, and output. The input layer is encoded and stored in the hidden layer, which includes a compressed representation. The output layer reconstructs the input layer and calculates the difference with an error function. Autoencoders are self-supervised algorithms.
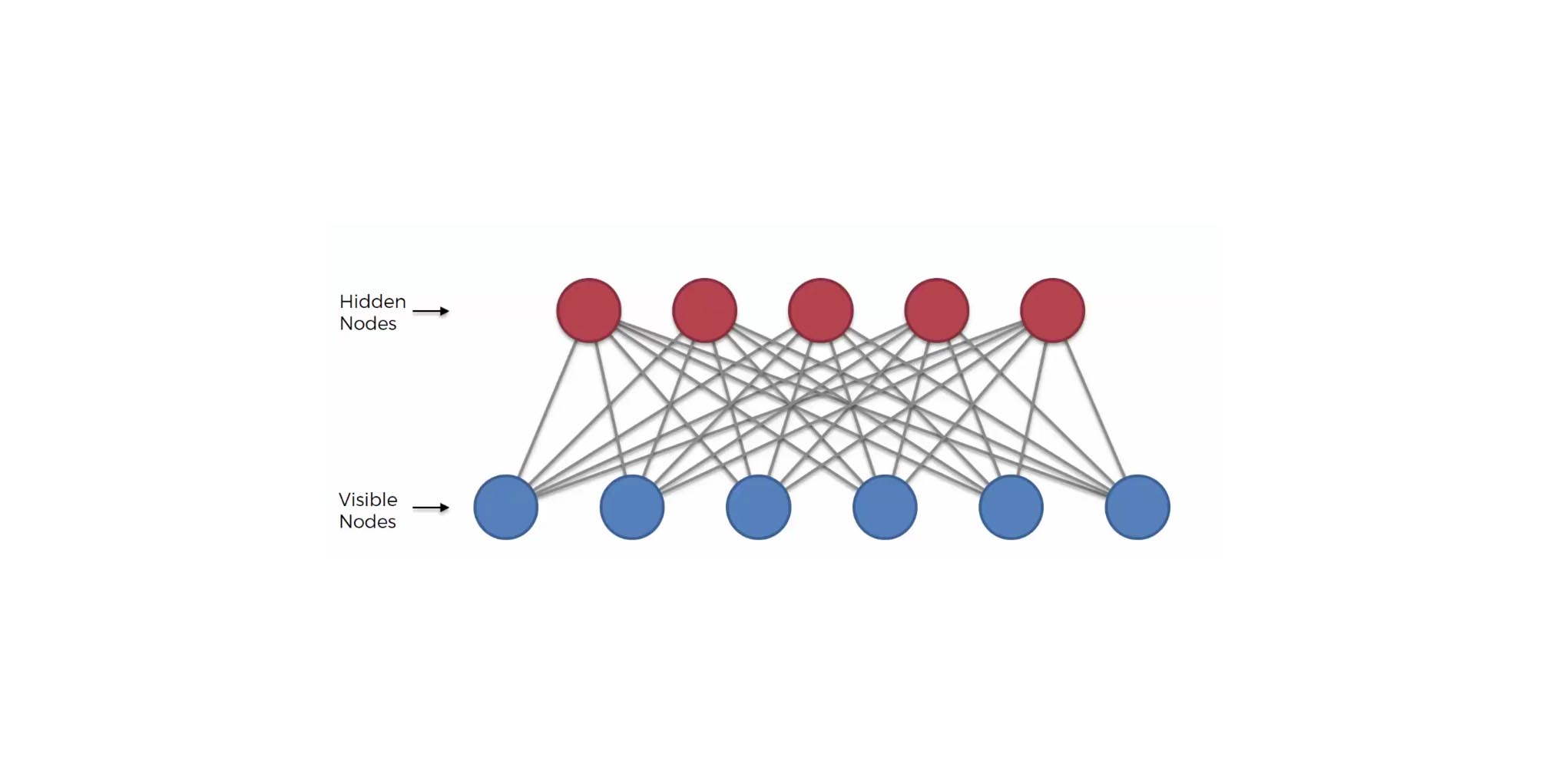
Restricted Boltzmann machine (RBM): RBMs, originally invented by Paul Smolensky in 1986, are 2-layered neural networks with input and hidden layers. They are known as generative models because the reconstructed input is always different from the original input. RBMs calculate the probability distribution of the training set using a stochastic approach, activating each neuron at random. They have built-in randomness, resulting in different outputs compared to deterministic models. Examples of RBM applications include dimensionality reduction and collaborative filtering.
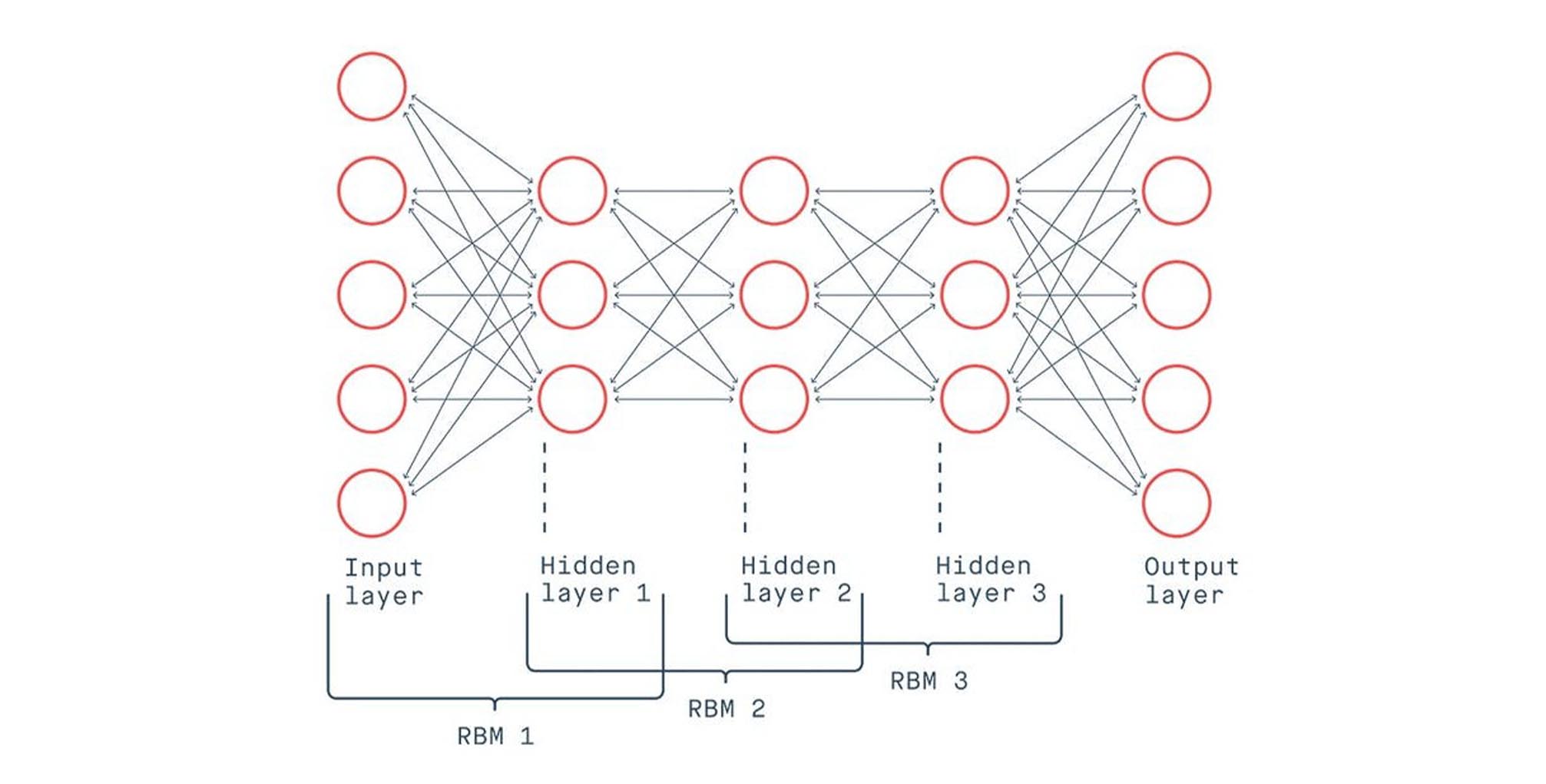
Deep belief networks (DBN): The Deep Bayesian Network (DBN) is a multilayer network with a unique training algorithm. It is represented as a stack of RBMs, with the input layer representing raw sensory inputs and the hidden layers learning abstract representations. Training involves unsupervised pretraining and supervised fine-tuning, with each layer reconstructing its input and applying labels to output nodes. Applications include image recognition, information retrieval, natural language understanding, and failure prediction.
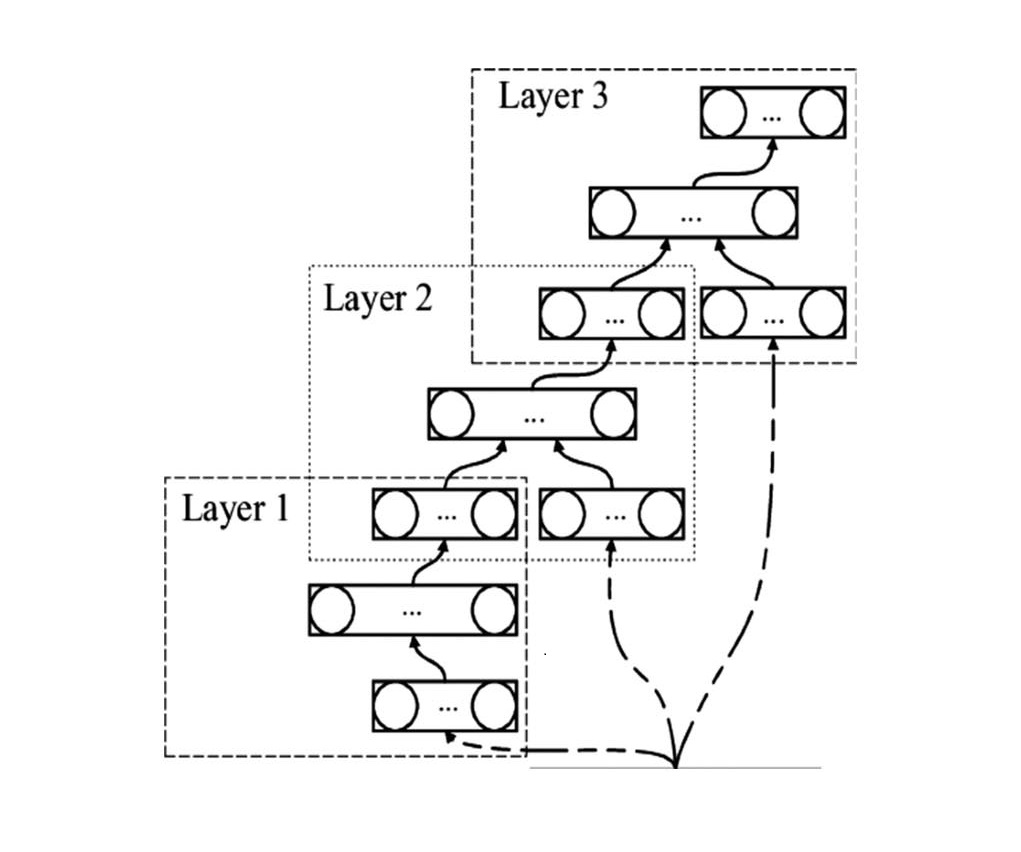
Deep stacking networks (DSNs): A deep convex network (DSN) is a deep network architecture that consists of individual networks with hidden layers, addressing the complexity of training. DSNs view training as a set of individual problems rather than a single problem. Each module in the DSN consists of an input, hidden, and output layer, allowing for more complex classification. DSNs can train individual modules in isolation, making them efficient for parallel training. Applications include information retrieval and continuous speech recognition.
For more articles:
—— > Where is Deep Learning used?
—— > Deep Learning Tech
—— > ML vs DL vs NN
—— > What is ML?